


Un Transformer es un tipo de arquitectura de aprendizaje profundo que utiliza una estructura de atención para procesar secuencias de texto. A...
1 minutos de lectura
28/06/2020
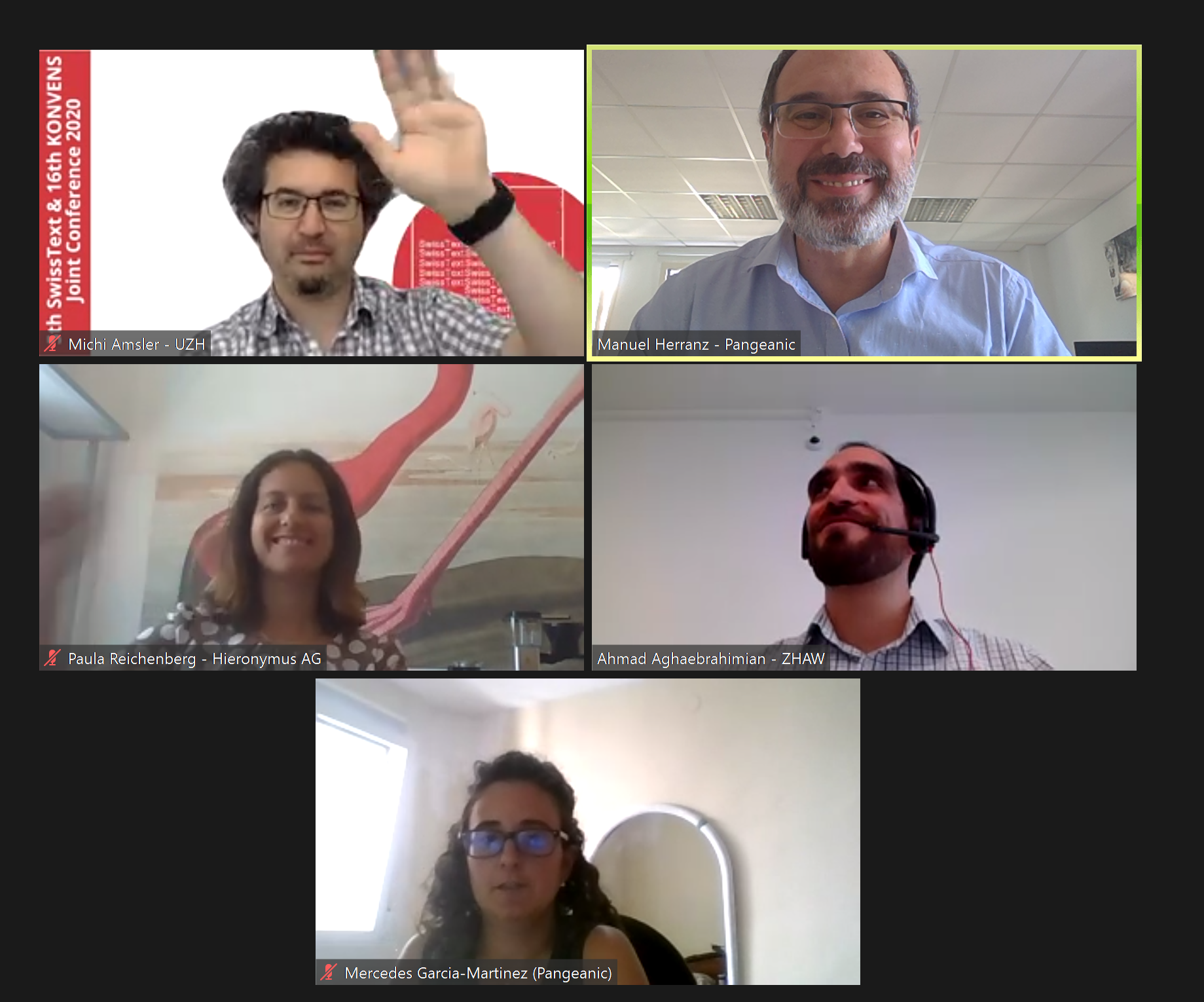
Pangeanic ha participado en la conferencia SwissText & KONVENS 2020 presentando “ The “Multilingual Anonymisation Toolkit for Public Administrations” (MAPA) Project”. MAPA es uno de los proyectos CEF de la Unión Europea junto al proyecto NTEU que está liderando Pangeanic. El equipo técnico PangeaMT está desarrollando una herramienta que permita anonimizar texto en cualquiera de las lenguas oficiales europeas, el equipo de lingüistas se encarga de anotar los corpus que se están creando para entrenar los modelos neuronales que permitan predecir el texto que lleva datos personales para desidentificarlo. Estos modelos están basados en reconocimiento de entidades y clasificación e incluyen el modelo del lenguaje preentrenado basado en transformers BERT multilingüe que permitirá la transferencia de conocimiento de lenguajes ricos en recursos como el inglés a los lenguajes bajos en recursos como el maltés. Esta herramienta ayudará a las administraciones públicas europeas a compartir datos protegiendo la privacidad y cumpliendo con los requisitos de RGPD. El código se compartirá como open-source para ayudar en el desarrollo de esta tecnología. El proyecto se realiza junto con Tilde, CNRS, ELDA, la universidad de Malta, Vicomtech y SEDIA como partners.  Este año la conferencia SwissText & KONVENS 2020 tenía lugar en Zúrich pero hemos asistido de modo virtual por teleconferencia. Se ha celebrado entre los días 23 y 25 de junio. El primer día se realizaron varios Workshops sobre tareas de procesamiento del lenguaje natural en alemán y los otros dos días ha consistido en presentaciones de keynotes y varias sesiones en paralelo sobre reconocimiento de voz, biomedicina, modelos del lenguage preentrenados, business y análisis de texto y sentimiento. La presentación de MAPA ha tenido lugar bajo la sesión de business el último día ha tenido interés en la comunidad.
Este año la conferencia SwissText & KONVENS 2020 tenía lugar en Zúrich pero hemos asistido de modo virtual por teleconferencia. Se ha celebrado entre los días 23 y 25 de junio. El primer día se realizaron varios Workshops sobre tareas de procesamiento del lenguaje natural en alemán y los otros dos días ha consistido en presentaciones de keynotes y varias sesiones en paralelo sobre reconocimiento de voz, biomedicina, modelos del lenguage preentrenados, business y análisis de texto y sentimiento. La presentación de MAPA ha tenido lugar bajo la sesión de business el último día ha tenido interés en la comunidad.
Este año la conferencia SwissText & KONVENS 2020 tenía lugar en Zúrich pero hemos asistido de modo virtual por teleconferencia. Se ha celebrado entre los días 23 y 25 de junio. El primer día se realizaron varios Workshops sobre tareas de procesamiento del lenguaje natural en alemán y los otros dos días ha consistido en presentaciones de keynotes y varias sesiones en paralelo sobre reconocimiento de voz, biomedicina, modelos del lenguage preentrenados, business y análisis de texto y sentimiento. La presentación de MAPA ha tenido lugar bajo la sesión de business el último día ha tenido interés en la comunidad.